NLPの進化:断片化されたAIから基盤モデルへ
定義
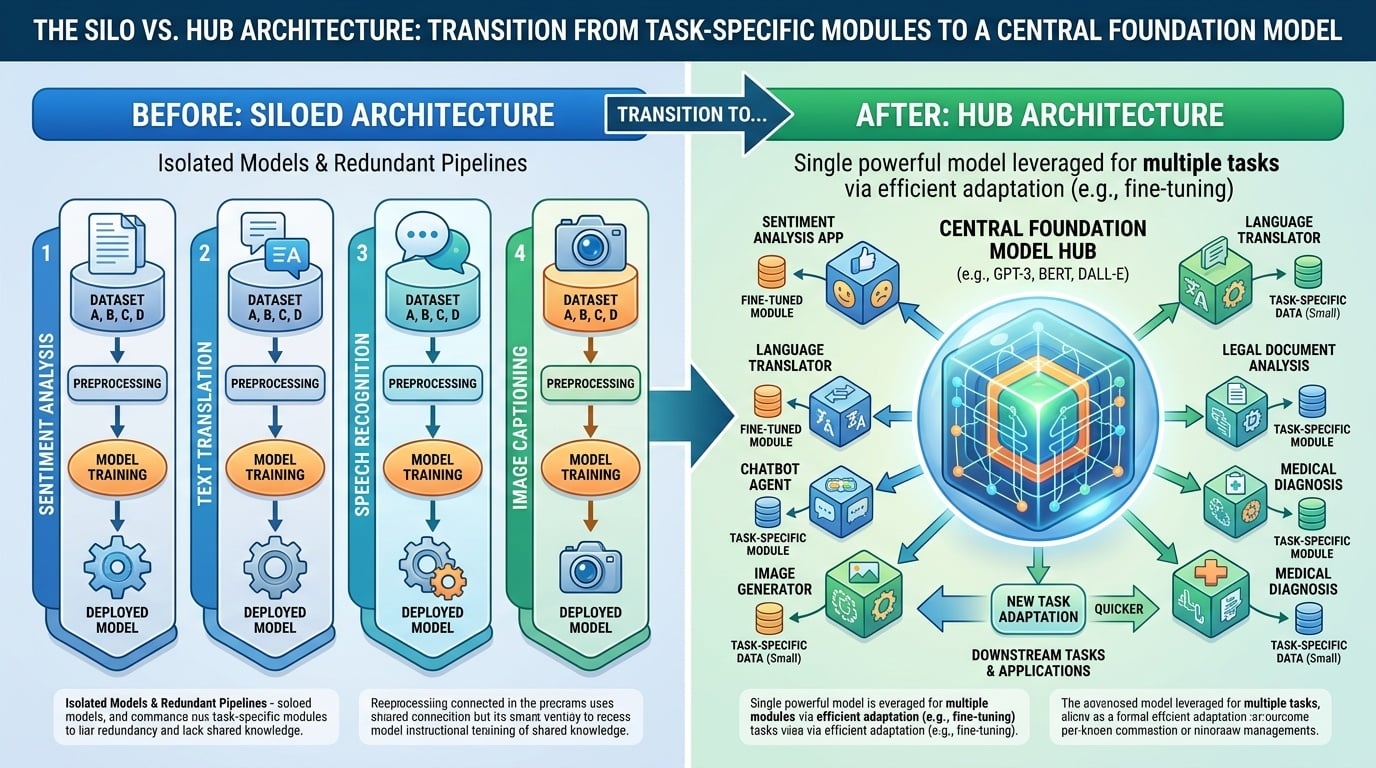
- 断片化されたAI:シーケンスラベリングや分類などの個別タスク向けに設計された、独立した専門的なニューラルアーキテクチャで特徴づけられる時代。
- 基盤モデル:すべての言語的問題を生成的なテキスト対テキストのシーケンス $x \rightarrow y$ として扱う、統合的かつモノリシックなトランスフォーマー構造。
核心概念
- アーキテクチャの統合: 歴史的に、NLPは特定のパイプライン(NERにはBi-LSTM、感情分析にはCNN)が必要だった。大規模言語モデル(LLM)はこれらの分離された領域を一つのバックボーンに統合し、同じ重みがすべてのタスクに使用される。
- 統一インターフェース: LLMは専用の「出力ヘッド」(例:3クラスのSoftmax)を自然言語インターフェースに置き換える。入力と出力は常に文字列であり、モデルは「意図」を解釈するようになる。 意図 ではなく 形式。
- 知識の転送: 従来のモデルは各タスクに対して「白紙状態」であった。LLMは 一般化第一を優先し、具体的なタスクは既存の堅牢な言語内部表現の応用にすぎない。
歴史的文脈
- 2018年以前: タスクの分離は、異なる損失関数 $\mathcal{L}_{task}$ を持つ別々のモデルの学習を必要とした。
- 現代の時代: 「テキスト対テキスト」のパラダイムにより、単一のモデル(例:Llama-3)がゼロショットまたはフェイショットプロンプトによってタスクを切り替えられる。
Python実装の比較